
Real-time identification based shipborne network transmission optimization algorithm

-
摘要:目的 提出一种基于实时性区分的舰载网络传输优化算法−实时延迟(real time delay based,RTDB)算法。方法 该算法根据不同类型报文的实时性需求对其进行分类,并指定不同的阈值,通过对报文的类型进行判定和处理来保证各报文的实时性需求。结合美国海军广泛使用的战术数据链Link11,Link16对算法增益进行分析。结果 理论分析表明,在业务数据量大于网络传输带宽,或业务生成率满足确定性分布的情况下,RTDB算法能带来一定的时延增益;使用NS3作为仿真平台并进行仿真分析,仿真结果与理论分析结果基本一致。结论 所提出的RTDB算法部署代价小,对于急需进行海军现代化改装的国家具有较重要意义。Abstract:Objectives This paper proposes a real-time identification based algorithm named RTDB.Methods The algorithm classifies messages by the real-time requirements of different types of them, and assigns different thresholds to them. The algorithm gain is then analyzed by combining Link 11 and Link 16, which are widely used by the US Navy.Results Theoretical analysis shows that the algorithm can bring a certain delay gain when the data rate is greater than the network transmission bandwidth or the generation rate satisfies the deterministic distribution. In this paper, NS3 is used as the simulation platform, and the gain of the proposed algorithm is simulated and analyzed, yielding the same results as the theoretical results.Conclusions The deployment cost of the proposed RTDB algorithm is small, and it can be of great significance for countries that urgently need to modernize their navies.
-
Keywords:
- shipborne network /
- transmission optimization /
- real-time /
- NS3
-
0. 引 言
随着科学技术的进步,海战已由机械化转型为信息化,并逐步向智能化发展。随着反舰导弹的高速化、智能化与集成化,战场形势愈发瞬息万变。尤其是在无人机上舰的情况下,舰艇对无人机的操控使得对信息传输的实时性要求越来越高。
众所周知,海军作战体系主要由海军舰艇、航空兵、岸基指挥所等单位构成,在常规训练及作战条件下,编队核心指挥舰同时与舰载机、岸基指挥所进行信息交互,此时舰载网络需要同时收发海、陆、空三大种类的业务情报。相比机载网与车载网,舰载网存在情报信息量大、信息源种类多、信息突发性强等特点。一般情况下,当业务量较低时,报文的实时性可满足要求,但一旦存在多跳中继传输,或者出现舰载机、潜艇以及多艘舰艇组成的混合编队进行立体作战情况,由于装备条件限制,极有可能出现大量报文位于队列待发而阻塞无线网络的现象。一些时效性要求较高的报文会因等待时延过长而极大地降低报文的时效性,舰艇将因不能有效掌握实时战场态势并发挥自身的作战效能,而造成损毁甚至是作战失败。显然,提高报文的实时性传输能力已成为当前急需,国内外针对该问题开展了大量研究,包括通过优化编解码提高空口传输效率、通过资源调度提高MAC吞吐量、通过自适应资源匹配提升网络容量等方式提高网络传输速率,使所有报文的时效性都可得到有效提高等,但带来的问题是对硬件要求高或是部署代价较大。
本文将在分析美军广泛使用的战术数据链Link11,Link16[1]优化方式的基础上,基于报文的实时性需求进行筛选区分,以减少部署代价的方式按需提高各类报文的时效性,从而满足各类报文对实时性的要求,使作战舰艇具备发挥其最大作战效能的能力。
1. 研究现状
当前,国内外对于战术数据链Link11的优化研究主要集中在组网与编码上,提出了3种优化组网方式的改进模型:第1种是基于优先级的组网改进模式;第2种是基于统计概率的组网改进模式;第3种是基于自组网思想衍生的动态组网改进模式[2],以及通过改进用于Link11的咬尾卷积码的译码算法来优化Link11的传输编译码性能[3]。
对数据链Link16的优化研究主要集中在时分多址(time division multiple access,TDMA)与时间同步上。其中,TDMA的优化算法主要是进行动态时隙分配,包括周期预约和有限竞争。基于节点邻域信息的TDMA协议(TDMA protocol based on node neighborhood information,TDMA-NNI)协议[4]将时域周期性地分为控制时隙和信息时隙,通过在控制时隙侦听收到的控制报文信息,为每个节点建立邻居节点时隙占用表,并在控制时隙进行周期性更新,然后根据最新的占用表实时性地在信息时隙预留和释放时隙。基于集中式TDMA的MAC(centralized TDMA based MAC,CTMAC)协议[5]按地理位置将节点划分为簇,每个簇存在1个中心节点,该节点负责对簇内的其他节点进行时隙调度。该协议将时域分为多个时帧,每个时帧由2个时隙集组成,相邻2个中间节点各使用1个时隙集,并对集中的时隙进行调度。采用划分2个时隙集的方式可减小节点簇间的相互干扰。时分多址接入(time spread multiple access,TSMA)协议[6]将时域分为时隙,并为每个节点分配等长的二进制码,二进制码中每个比特位对应一个时隙,当节点的二进制码中比特位对应为1时,允许该节点在该时隙发送报文。基于TDMA的调度算法[7]将每个时隙设置为5 ms,并将时域以40个时隙为周期进行分割,每个周期由4个时隙的控制域和36个时隙的数据域构成。各节点在控制域分配虚拟ID(virtual ID,VID),然后根据分配的VID在数据域进行数据传输。该协议通过分配VID的方式降低竞争信道的节点数量。
传统的时间同步方法认为询问帧与应答帧的传播时间一致,此时,单一节点的瞬时时延变化会导致同步误差抖增以及链路震荡。节点间时间同步的优化方法可同时修正网内所有节点的时隙位置、减小单个节点的时隙位置偏差对同步过程的影响,以及降低整个时间同步过程耗费的时间代价[8]。
综上所述,当前对于数据链Link11和Link16的优化研究主要是提高吞吐率、降低节点收发报文冲突率以及改进时间同步机制。在实际作战场景中,舰舰、舰岸与舰机间收发的消息报文主要包括情报类消息报文和筹划类消息报文等[9]。其中情报类消息(包括航迹、文电等)对报文的时效性要求很高,尤其是火控级情报类消息,端到端的时延越大,报文时效性越低;而筹划类消息,诸如作战计划、卫星云图等对实时性的需求则较低。对于存在大量信息交互的作战场景,链路负载如果超出舰艇的信息处理能力,就会导致链路阻塞,影响舰艇的信息获取能力,甚至是影响整个战场的走势。
因此,将基于实际的作战需求以及报文的时效特性,提出一种基于实时性区分的舰载网络传输优化算法−RTDB算法,并结合美国海军广泛使用的数据链Link11和Link16,分别从理论推导和仿真验证的角度分析该算法的传输优化增益。
2. RTDB算法
本节主要对新的报文结构和算法运行机制进行分析,以实时性区分报文,这是对RTDB算法进行优化的前提。
2.1 报文结构
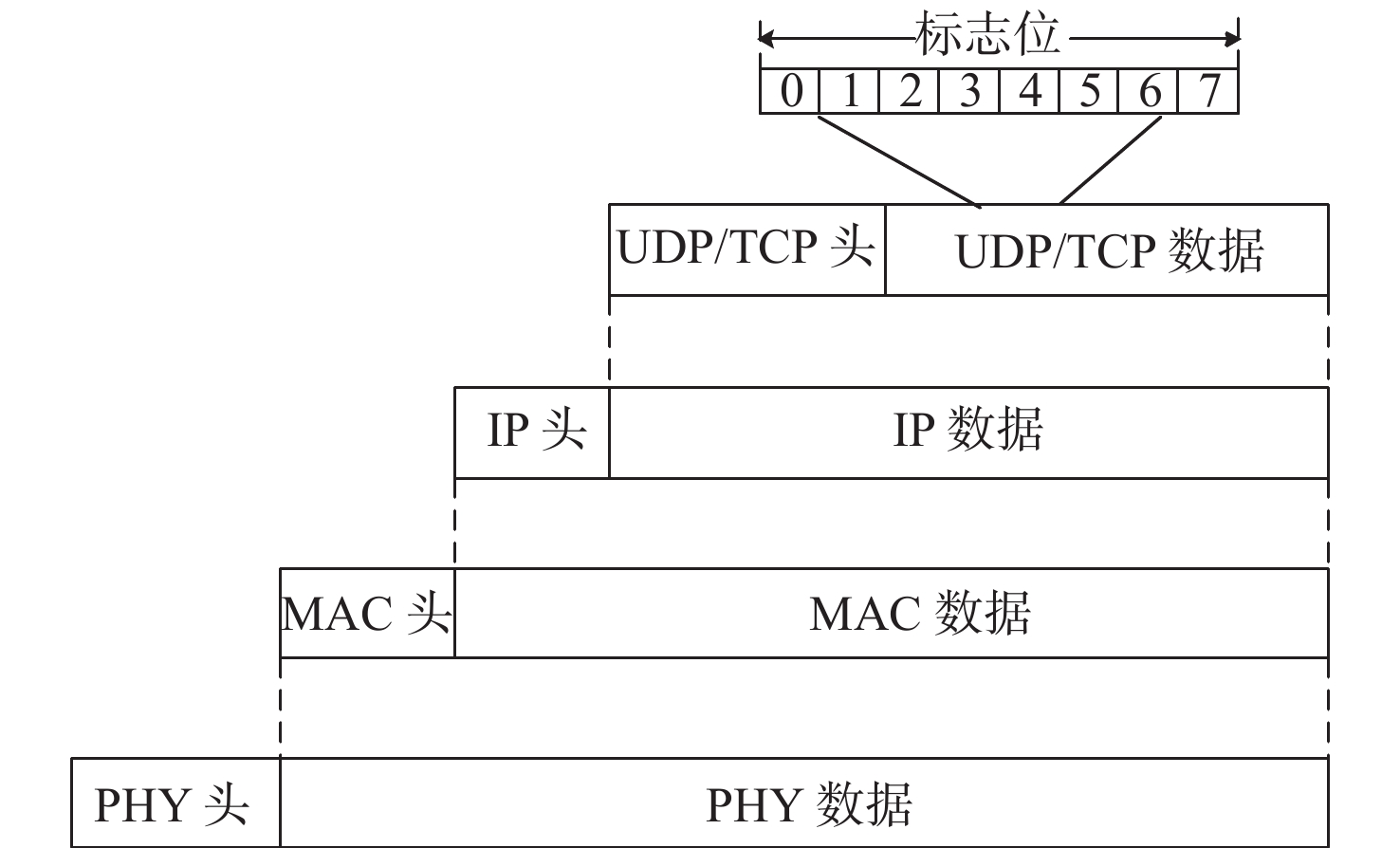
在报文中额外增加1个字节来作为实时性标志位字段,如图1所示,图中UDP为用户数据报协议;TCP为传输控制协议;IP为网际互连协议;MAC为介质访问控制;PHY为以太网物理层数据收发器。具体字段内容如下。
Bit 0:
1 表示实时性;
0 表示非实时性。
Bit 1~ Bit 7:
0 表示普通航迹报文;
1 表示精跟航迹报文;
2 表示普通文电;
3 表示加急文电;
4 表示特急文电;
其他:备用。
2.2 RTDB算法
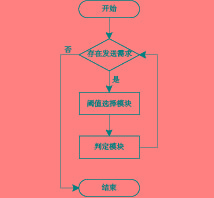
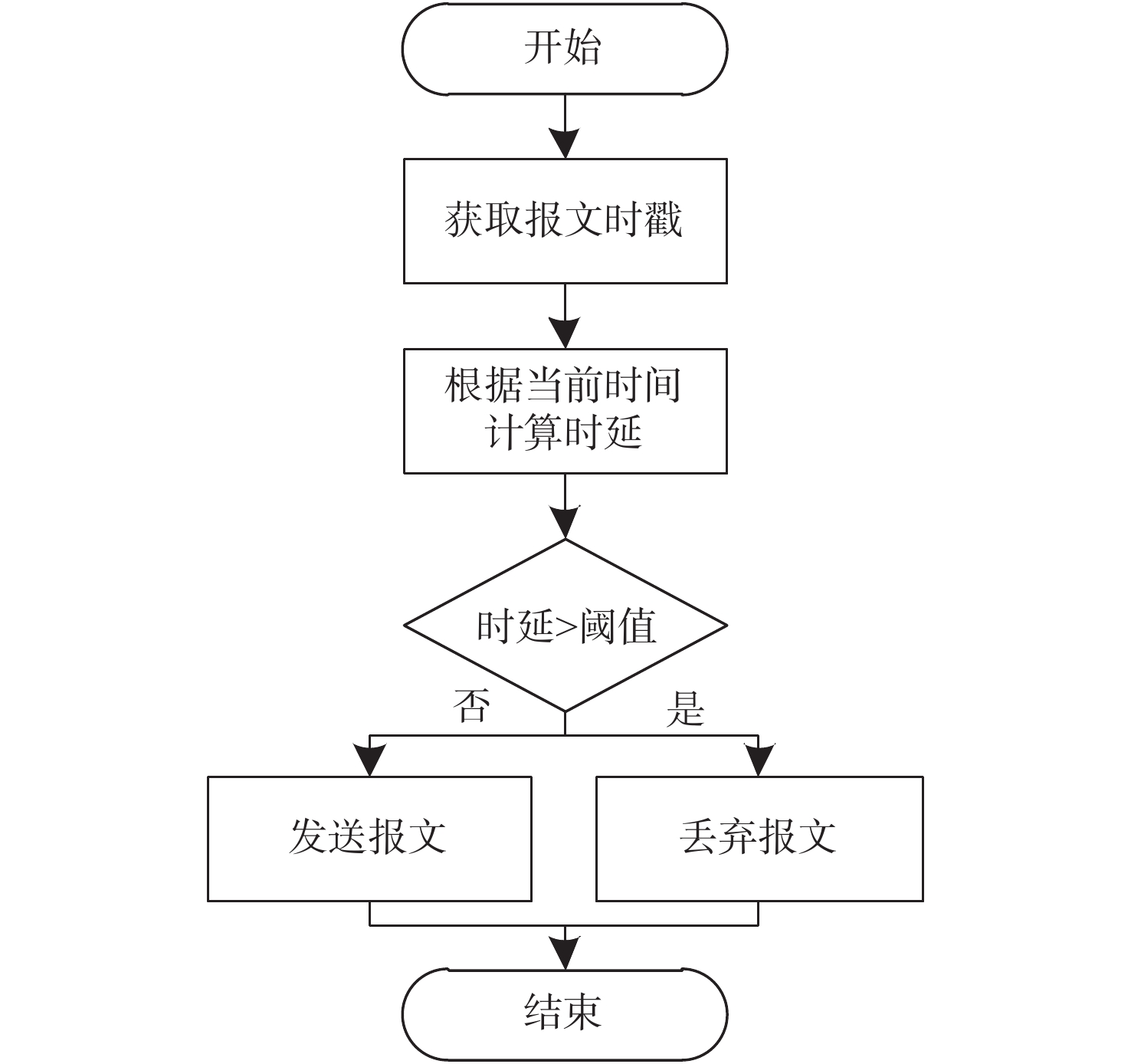
RTDB算法主要由2个模块构成:阈值选择模块和判定模块。阈值选择模块根据报文的实时性需求为不同类型的报文分配不同的时延阈值。时延阈值的定义为:若报文的排队时延超过该阈值,认为该报文失去时效性。判定模块将报文实际时延与阈值选择模块给出的报文阈值进行比较,然后根据比较情况对报文进行不同的处理。图2所示为整个算法的运行流程。
节点首先对自身的发送队列进行轮询,若是当前处于该节点的发送时隙并且该节点有发送需求,则解析该报文的实时性标志位字段。根据发送队列中报文的实时性以及实时性类型,选择相应的阈值。然后,进入判定模块,解析报文时戳,并根据当前时间与报文时戳的差值计算报文的排队时延。接着,对得到的时延与当前阈值进行比较,根据比较结果对报文进行处理。报文处理结束后,再次进入轮询过程,若是该节点的发送队列依然有报文待发并且依然处于该节点的发送时隙,则进入下一个报文的处理流程,否则,该节点进入等待过程。
2.2.1 阈值选择模块
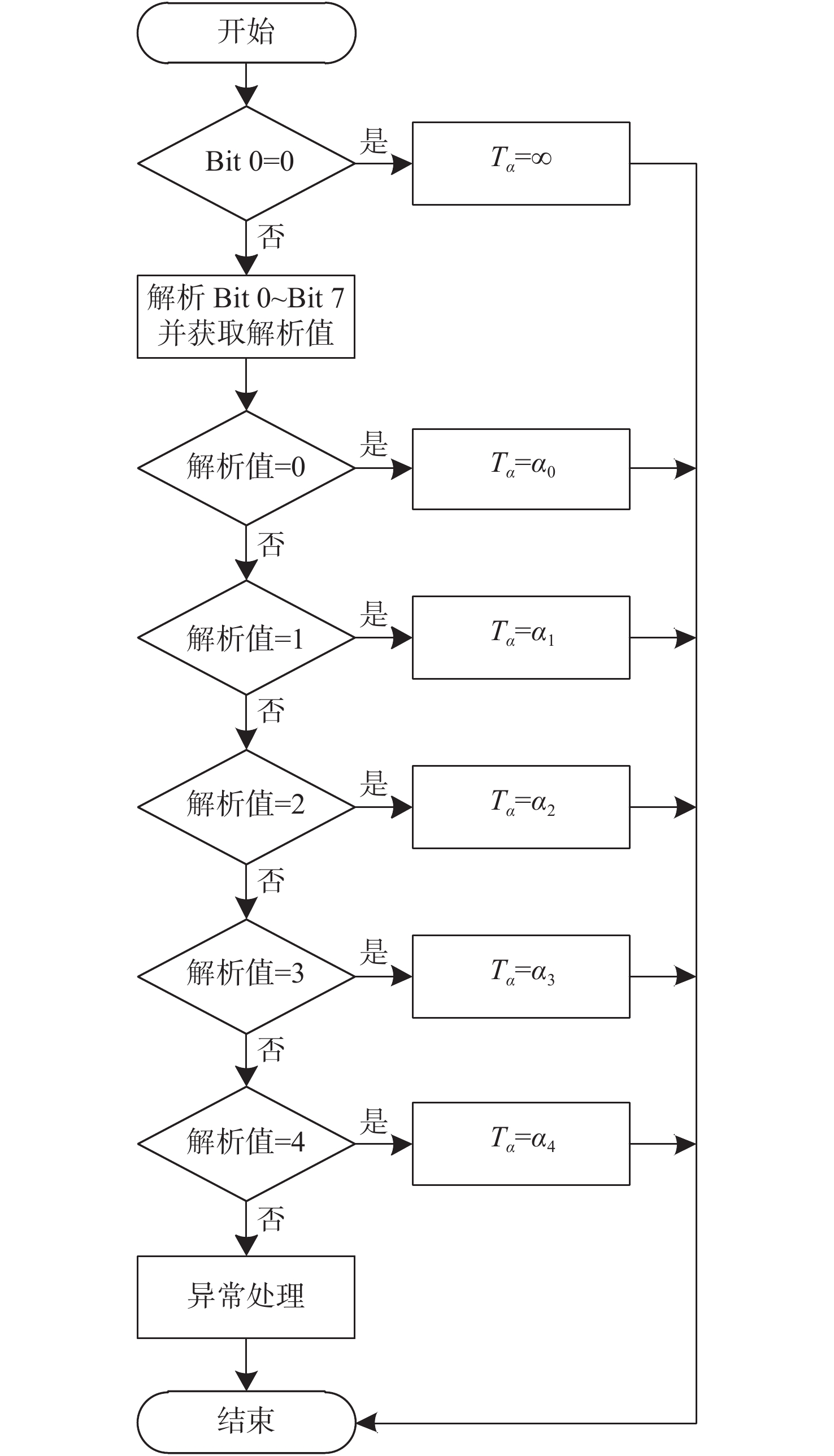
阈值选择模块的具体流程如图3所示。
对于进入阈值选择模块的报文,首先对报文实时性标志位字段的Bit 0进行解析并获取报文的实时性,若是报文Bit 0为0,说明该报文属于非实时性报文,将当前的时延阈值
Tα 设置为无限大(当前可设定值的最大值),之后退出本模块;若Bit 0为1,说明该报文属于强实时性报文,需进一步对Bit 1~Bit 7进行解析,并根据解析结果分别将Tα 置为不同的阈值量αi (i=0,1,2,3,4)。若是解析值为0,说明该报文属普通航迹报文,设置时延阈值Tα=α0 之后退出本模块;若是解析值为1,说明该报文属精跟航迹报文,设置时延阈值Tα=α1 之后退出本模块;若是解析值为2,说明该报文属普通文电报文,设置时延阈值Tα=α2 之后退出本模块;若是解析值为3,说明该报文属加急文电报文,设置时延阈值Tα=α3 之后退出本模块;若是解析值为4,说明该报文属特急文电报文,设置时延阈值Tα=α4 之后退出本模块;若是解析值为备用值,则进入异常处理机制,将时延阈值Tα 设置为无限大之后退出本模块,然后进入判定模块。2.2.2 判定模块
判定模块的具体流程如图4所示。
判定模块调用Linux系统内核定义的gettimeofday函数与timeval结构体。gettimeofday函数用于获取当前时间,timeval结构体存在2个变量tv_sec与tv_usec,分别以秒和微秒粒度承载获取的时间量。对于进入判定模块的报文,首先对报文的时戳进行解析并获取报文产生时间,声明timeval结构体,调用gettimeofday函数获取当前时间,对2个时间值进行差值计算,获取报文从产生到准备发送过程的时延值;然后,将该时延值与在阈值选择模块中得到的时延阈值进行比较,若是出现时延值大于该实时性报文对应阈值的情况,对该报文进行丢弃处理后退出本模块,否则,立即进入正常的发送过程,然后退出本模块。
3. 算法理论分析
网络中,各个报文的端到端时延Td主要由4部分组成[10]:从设备发送报文的第1个比特算起,到该报文的最后一个比特发送完毕所需要的传输时延Tdt;报文在信道介质传输时的传播时延Tdr;报文在发送队列中等待的排队时延Tdq;设备收到报文后的处理时延Tds。
设当前数据报文大小为Sp,信道带宽为
R ,节点间的传输距离为D ,电磁波在信道中的传播速率为c ,节点处理报文的时间为q ,则有Tdt=SpR (1) Tdr=Dc (2) Tds=q (3) 接下来,通过计算分组中的排队用户数
N 来计算排队时延Tdq。对于作战舰艇,这里采用排队论模型[A/B/C]:[d/e/f]来分析稳态情况下舰载网络中各节点进行信息交互时各个报文的排队时延[11]。其中:A为到达率,这里指节点对外通信报文的生成速率;B为处理速率,这里指空口发送速率;C为服务员数量,这里指各节点对外通信设备数;d为最大排队容量;e为信息总体数量;f为处理规则。
对于舰载节点来说,其报文发送速率是固定的,因此排队系统可以采用[M/Ds/Cs]/[Nm/∞/FCFS]排队模型进行描述。其中M为报文到达队列的过程为无记忆的泊松过程;Ds为报文的处理时间,服从确定性分布;Cs为舰载节点向外发送报文的通道数量;Nm为各个通道队列的最大容量;∞为不考虑报文数量限制对报文排队时延的影响;FCFS(first in first out)为优先处理先进入队列的报文。根据Little定理,对于任意一个排队系统,在统计平衡的情况下,排队用户数N为
N=λTd (4) 式中,
λ 为报文到达队列的速率。假定C=1,
μ 为排队系统中的服务速率,下面分别对到达率λ<μ和λ≥μ这2种情况下的算法增益进行分析。首先分析λ<μ的情况。当到达率λ<μ时,根据P-K公式,稳态条件下Cs=1时排队系统的平均等待时间Tdq为
Tdq=λ¯X22(1−λμ) (5) 式中,
¯X2=E{X2} ,为服务时间的二阶矩。根据Little定理,此时排队系统中的平均队列长度Ndq为
Ndq=λTdq=λ2¯X22(1−λμ) (6) 这里
μ 可以等效为R。在R为常量的情况下,排队模型中服务时间的二阶矩¯X2 表示如下:¯X2=E{X2}=1μ2 (7) 则稳态条件下的等待时间
Tdq 为Tdq=λ¯X22(1−λμ)=λ·1μ·12(1−λμ)=λ2(μ−λ) (8) 此时,稳态条件下的端到端时延
Td 为Td=Tdt+Tdr+Tdq+Tds=SpR+Dc+λ2(μ−λ)+q (9) 设当前排队系统的阈值为
Tα ,则使用RTDB算法后稳态条件下的时延Td′ 为T′d∈[SpR+Dc+q,SpR+Dc+Tα+q] (10) RTDB算法的增益
G 为G=Td−T′dTd (11) 将式(9)和式(10)代入式(11),得
G∈[0,max (12) 接着,分析λ≥μ的情况。当到达率λ≥μ时,理论上会导致系统中的排队报文数趋于无穷大。针对这种情况,工程上应用的处理方法是设置最大发送队列长度Nqm和最大排队时延Tdqm。只要Tdq >Tdqm或者Nq>Nqm,无论是实时性报文还是非实时性报文,均会被丢弃。因此,可以认为当排队系统达到动态平衡时,排队时延
{T}_{\rm{dq}}=\mathrm{min}({T}_{\rm{dqm}},\; {N}_{\rm{qm}}\cdot {T}_{\rm{dt}}) 。由于使用算法后的时延{T_{\rm{d}}'} 为{T_{\rm{d}}'} \in \left[ {\frac{{{S_{\rm{p}}}}}{R} + \frac{D}{c} + q,\;\frac{{{S_{\rm{p}}}}}{R} + \frac{D}{c} + {T_\alpha } + q} \right] (13) 根据式(11)和式(13),所提出的RTDB算法在λ≥μ时的增益
G 为G\in \left[0,\;\dfrac{\mathrm{max}(0,\;\mathrm{min}({T}_{\rm{dqm}},\;{N}_{\rm{qm}}\cdot {T}_{\rm{dt}})-{T}_{\alpha })}{\dfrac{{S}_{\rm{p}}}{R}+\dfrac{D}{c}+\mathrm{min}({T}_{\rm{dqm}},\;{N}_{\rm{qm}}\cdot {T}_{\rm{dt}})+q}\right] (14) 综上所述,所提出的RTDB算法的最大增益
{G_{\rm{m}}} 为{G}_{\rm{m}}=\left\{ \begin{aligned} & \dfrac{\mathrm{max}\left(0,\;\dfrac{\lambda }{2(R-\lambda )}-{T}_{\alpha }\right)}{\dfrac{{S}_{\rm{p}}}{R}+\dfrac{D}{c}+\dfrac{\lambda }{2(R-\lambda )}+q},\;\rm{ }\qquad\quad\quad\;\;\lambda \rm{<}\mu \\& \dfrac{\mathrm{max}(0,\;\mathrm{min}({T}_{\rm{dqm}},\;{N}_{\rm{qm}}\cdot {T}_{\rm{dt}})-{T}_{\alpha })}{\dfrac{{S}_{\rm{p}}}{R}+\dfrac{D}{c}+\mathrm{min}({T}_{\rm{dqm}},\;{N}_{\rm{qm}}\cdot {T}_{\rm{dt}})+q},\rm{ }\;\;\lambda \geqslant \mu \rm{ } \end{aligned}\right. (15) 4. 仿真分析
下面,对所提出的算法进行仿真分析。本文采用NS3仿真平台。NS3是一个基于GNU GPLv2兼容性开放源码许可的完全开源的开发工程,于2006年启动。同时,NS3是一款专业的通信仿真软件,其会话过程以节点为单位,在脚本中设置仿真场景并完成对节点的配置后即可启动仿真[12],具有能处理节点的多重接口、使用IP地址、与网络协议保持一致等[13]特点。
NS3的整体架构如图5所示。
仿真场景设置如图6所示。假定编队为最优化的菱形队形编队,即周边4艘从属舰以菱形排布,菱形的中心为主舰[14],4艘从属舰与主舰的距离均为5 km,舰艇保持相对静止。4艘从属舰均以相同的速率向主舰发送消息报文,舰载网络分别使用数据链Link11和Link16。假定当前只存在一种类型的实时性报文,并且实时性报文和非实时性报文之比为8∶2,Link11的传输速率选择为2 250 bit/s,Link16的传输速率为232 kbit/s,应用层报文长度固定为128 byte。在默认情况下,从属舰的发送队列最大容量为40 000,报文的最大排队时延为3 s。这里,设置RTDB算法的实时性报文阈值
{T_\alpha } =300 ms。接下来,分别在低负载和满负载下对使用RTDB算法和不使用RTDB算法的情况进行仿真,并对仿真结果进行分析。首先分析低负载情况。所谓低负载,即网络总业务速率远小于网络传输带宽的情况。对于Link11,这里分别将网络总负载设置为5,10,15,20,25和30 bit/s来进行仿真,得到的网络吞吐率、端到端平均传输时延如图7所示。
![]() 图 7 低负载情况下数据链Link11的网络吞吐率和端到端时延随网络负载的变化Figure 7. Variation of network throughput and end-to-end delay with network load of Link11 at low load condition
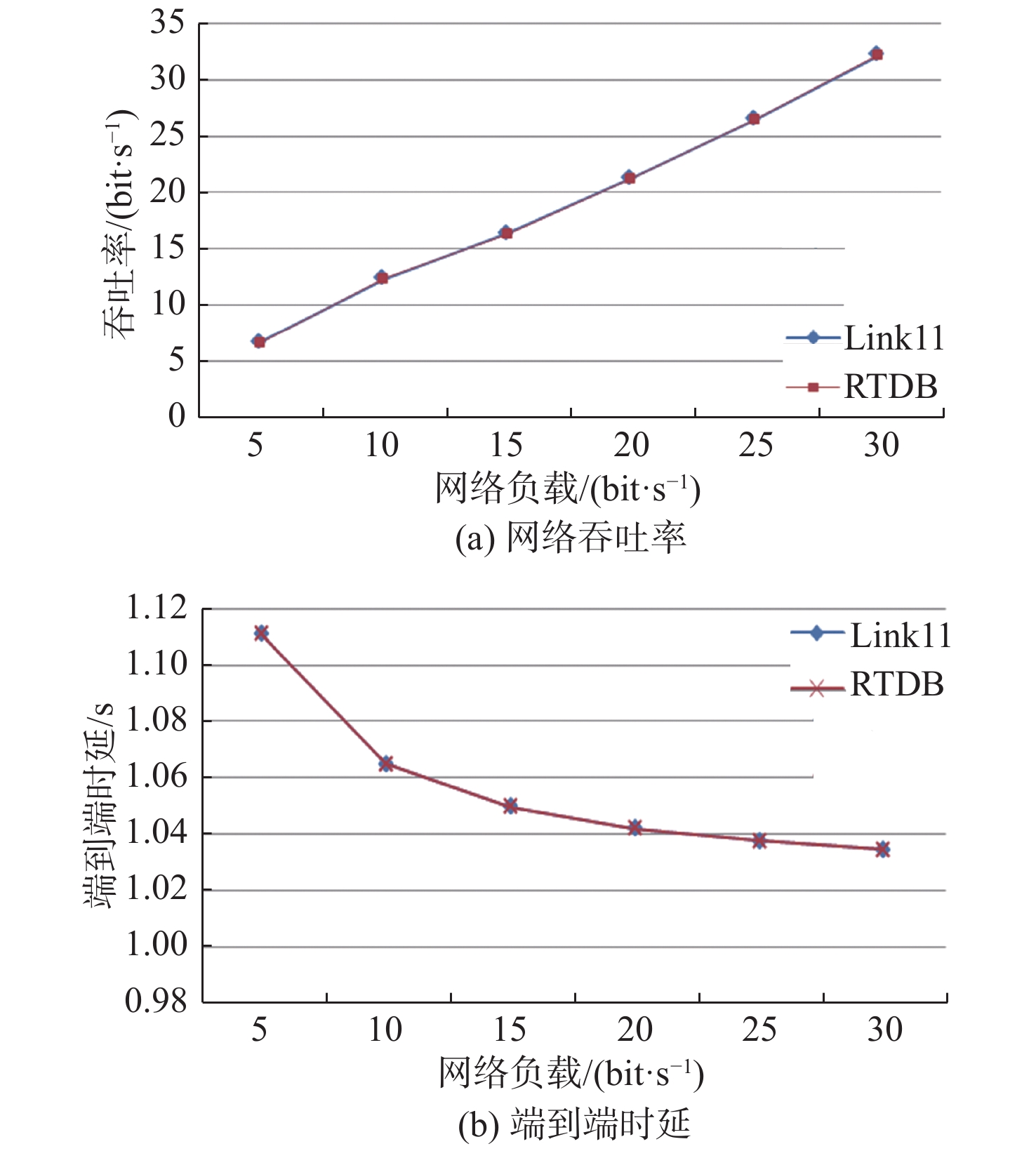
图 7 低负载情况下数据链Link11的网络吞吐率和端到端时延随网络负载的变化Figure 7. Variation of network throughput and end-to-end delay with network load of Link11 at low load condition对于Link16,这里分别将网络总负载设置为5,10,15,20,25和30 kbit/s进行仿真,得到的网络吞吐率、端到端平均传输时延如图8所示。
由图7和图8可知,在低负载情况下,不同网络负载下的网络吞吐率均略高于网络负载。这是因为网络负载是应用层速率,而网络吞吐率统计的是MAC层速率,MAC层相对于应用层会增加一定的头部开销,因此会出现吞吐率略高于网络负载的情况。
![]() 图 8 低负载情况下数据链Link16的网络吞吐率和端到端时延随网络负载的变化Figure 8. Variation of network throughput and end-to-end delay with network load of Link16 at low load condition
图 8 低负载情况下数据链Link16的网络吞吐率和端到端时延随网络负载的变化Figure 8. Variation of network throughput and end-to-end delay with network load of Link16 at low load condition数据链Link11的端到端时延与Link16的变化趋势一样,但Link11的时延要高于Link16。这是因为Link11的速率低,传输一个数据报文比Link16多200 ms;另外,Link11使用的是轮询呼叫模式,发送数据的前提是发送轮询帧并收到应答帧,因此每次在数据发送之前会存在收发轮询帧的时延。
另由图7和图8还可知,在低负载情况下,使用RTDB算法和未使用RTDB算法的网络中端到端平均时延与吞吐率随网络负载变化的趋势一致。其中,网络吞吐率随网络负载的增加而增加,端到端平均时延则随网络负载的增加而降低,且端到端平均时延及网络吞吐率的值一致。究其原因,当前传输带宽远大于业务生成速率时,可忽略排队情况和排队时延,故产生的报文都能被及时处理。因为RTDB算法主要是基于排队时延进行优化,因此2种情况下的端到端时延一致。由于NS3在初始化时会进行网络配置与寻址,导致初始处理时延较大,因而第1个报文的端到端时延会较大;后续报文在传输时则不会存在这种情况,所以后续报文的端到端时延一致并且均小于第1个报文的端到端时延。可以认为,第1个报文的端到端时延主要受初始处理时延影响,后续报文的端到端时延主要受处理时延影响。在低负载情况下,发送的报文数量与接收的报文数量一致,接收的报文数量随网络负载的递增而递增,而端到端平均时延因受初始处理时延的影响,是随网络负载的递增而呈降低趋势。
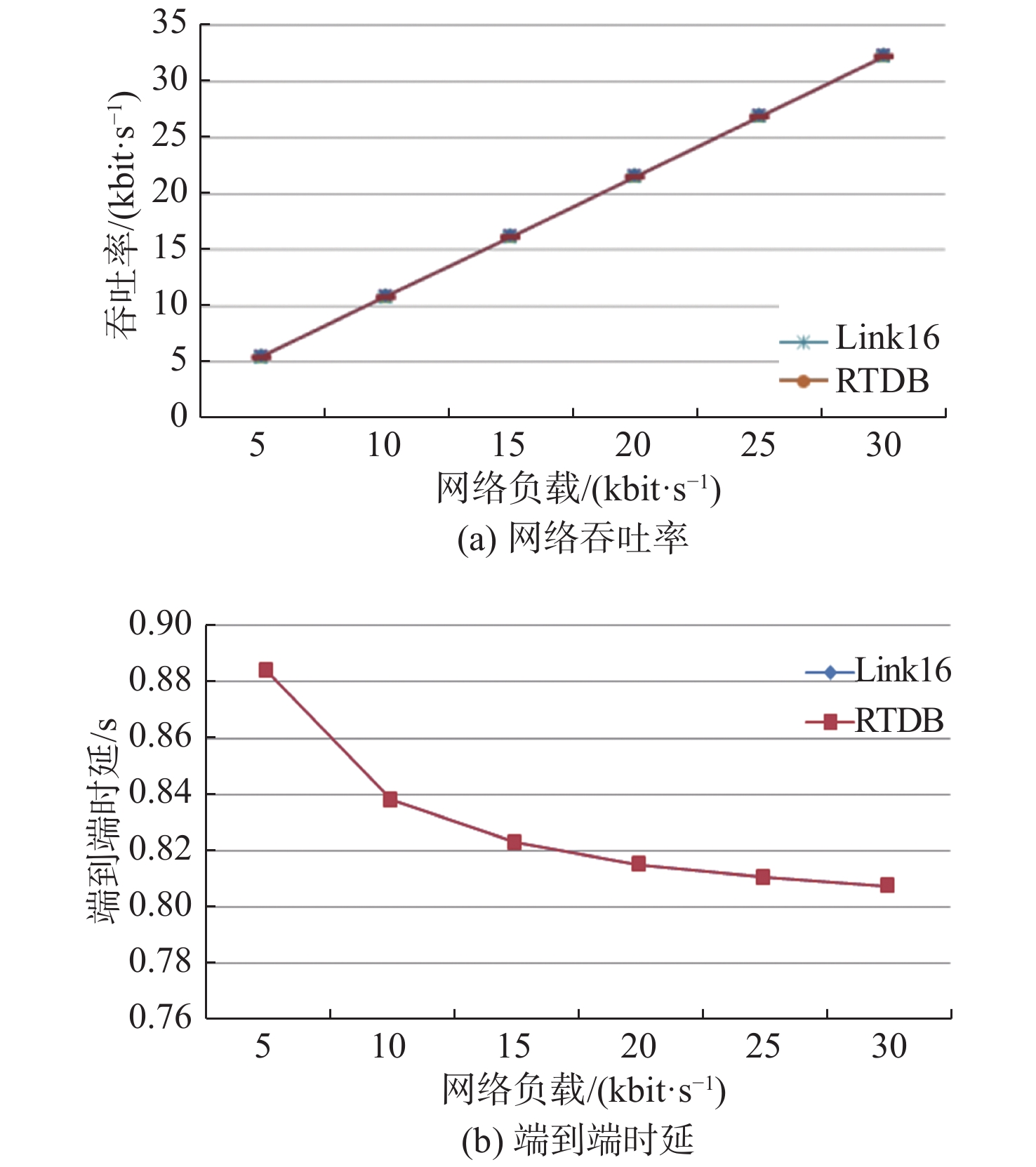
接下来分析中等负载情况。所谓中等负载,即网络总业务速率接近网络传输带宽的情况。针对Link11,这里分别将网络总负载设置为1 000,1 100,1 200,1 300,1 400和1 500 bit/s进行仿真,得到的网络吞吐率、端到端平均传输时延如图9所示。
![]() 图 9 中等负载下数据链Link11的网络吞吐率和端到端时延随网络负载的变化Figure 9. Variation of network throughput and end-to-end delay with network load of Link11 at middle load condition
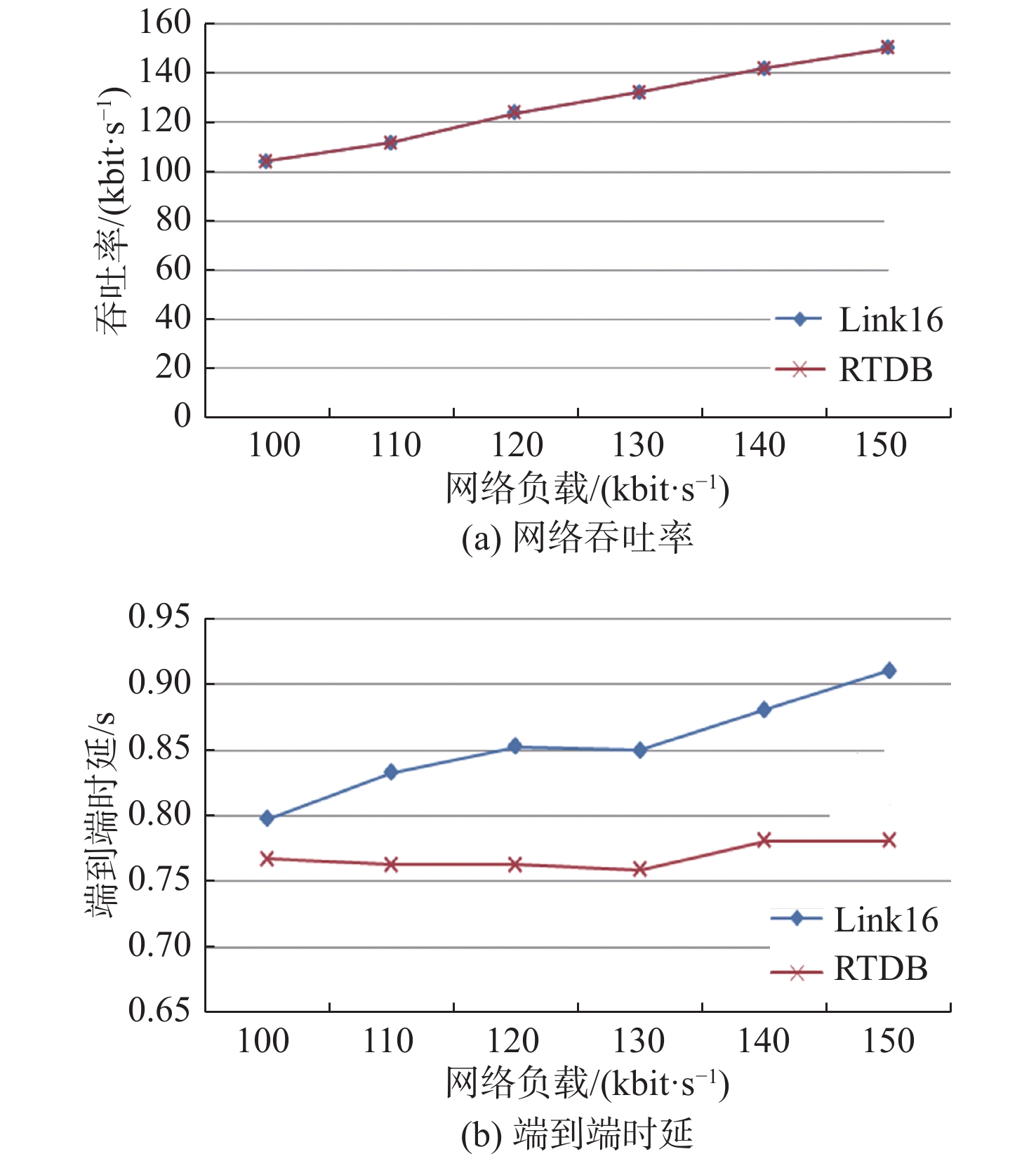
图 9 中等负载下数据链Link11的网络吞吐率和端到端时延随网络负载的变化Figure 9. Variation of network throughput and end-to-end delay with network load of Link11 at middle load condition针对Link16,分别将网络总负载设置为100,110,120,130,140和150 kbit/s进行仿真,得到网络吞吐率、端到端平均传输时延如图10所示。
![]() 图 10 中等负载下数据链Link16的网络吞吐率和端到端时延随网络负载的变化Figure 10. Variation of network throughput and end-to-end delay with network load of Link16 at middle load condition
图 10 中等负载下数据链Link16的网络吞吐率和端到端时延随网络负载的变化Figure 10. Variation of network throughput and end-to-end delay with network load of Link16 at middle load condition由图9和图10可知,在中等负载情况下,数据链Link11的吞吐率与Link16的变化趋势基本一致,但端到端时延的变化趋势差别较大。根据理论分析情况,计算当前Link11和Link16在只存在实时性报文稳态情况下的排队时延。Link11在网络负载为1 000 bit/s时的排队时延(单位:ms)为
{T_{{\rm{dq}}}} = \frac{\lambda }{{2(\mu - \lambda )}} = \frac{{1\;000}}{{2 \times (2\;250 - 1\;000)}} = 400 同理,可得Link16在网络负载为100 kbit/s时的排队时延为378 ms。
显然,由于Link11的空口传输速率较低,稳态排队时延已超过系统阈值,而随着网络负载越来越大,此时RTDB算法生效,实时性报文的稳态端到端时延在阈值处稳定,因此整个趋势呈先增加后平稳的状态。首先,分析网络负载为1 000 bit/s的情况。根据理论分析结果,代入
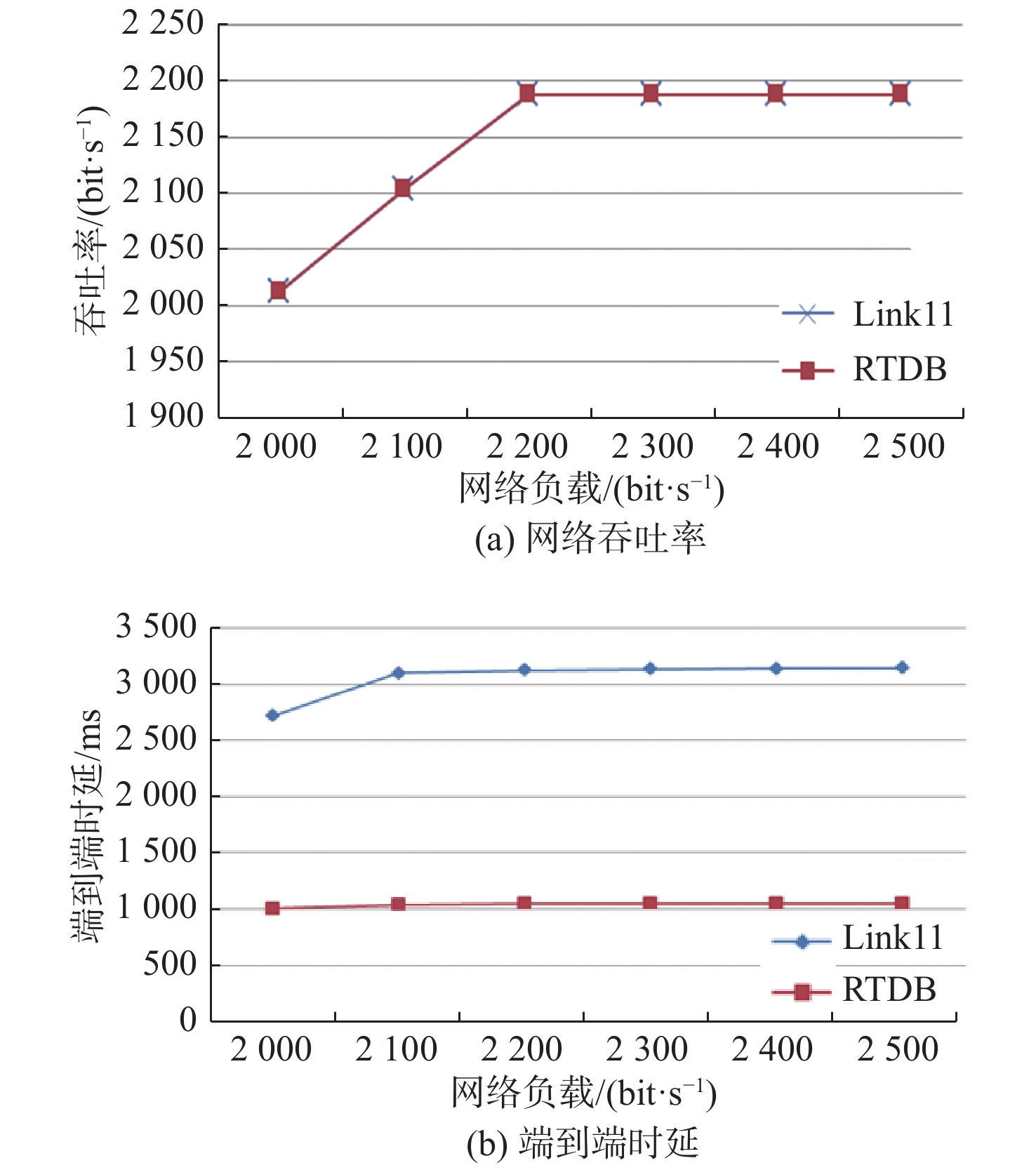
\lambda < \mu 时的增益公式(式(15)),得到Link11的最大增益为12.7%。仿真结果表明1 000 bit/s下的增益为11.4%,符合理论分析情况。同理,依次验证网络负载为1 100,1 200,1 300,1 400和1 500 bit/s时的情况,结果显示均符合理论分析结果。中等负载下Link16的稳态排队时延与Link11的基本一致,根据理论分析结果,代入\lambda < \mu 时的增益公式,得到中等负载下Link16的增益为8.4%,与仿真结果一致。最后分析满负载情况。所谓满负载,即网络总负载约等于或者大于网络传输带宽的情况。针对Link11,分别将网络总负载设置为2 000,2 100,2 200,2 300,2 400和2 500 bit/s进行仿真,得到网络吞吐率、端到端平均传输时延如图11所示。
![]() 图 11 满负载下数据链Link11的网络吞吐率和端到端时延随网络负载的变化Figure 11. Variation of network throughput and end-to-end delay with network load of Link11 at full load condition
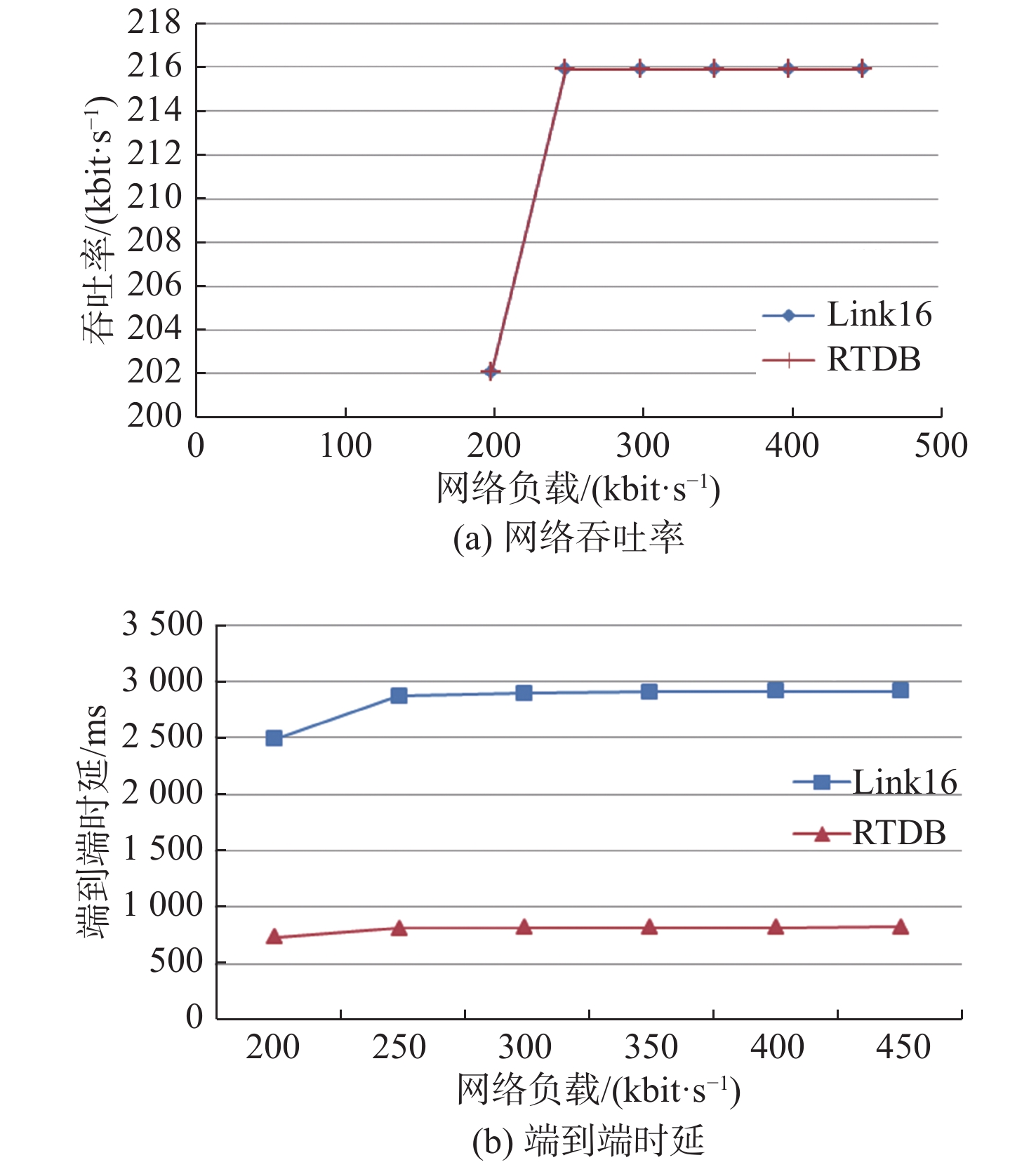
图 11 满负载下数据链Link11的网络吞吐率和端到端时延随网络负载的变化Figure 11. Variation of network throughput and end-to-end delay with network load of Link11 at full load condition针对Link16,分别将网络总负载设置为200,250,300,350,400和450 kbit/s进行仿真,得到网络吞吐率、端到端平均传输时延如图12所示。
![]() 图 12 满负载下数据链Link16的网络吞吐率和端到端时延随网络负载的变化Figure 12. Variation of network throughput and end-to-end delay with network load of Link16 at full load condition
图 12 满负载下数据链Link16的网络吞吐率和端到端时延随网络负载的变化Figure 12. Variation of network throughput and end-to-end delay with network load of Link16 at full load condition由图11和图12可知,在满负载情况下,数据链Link11和Link16的网络吞吐率均接近于网络传输带宽,即满负载情况下的网络吞吐率主要受网络传输带宽的影响。
使用RTDB算法的网络中端到端平均时延均小于未使用RTDB算法的网络。其主要原因是当业务生成速率大于或等于传输带宽时,Link16和Link11的稳态排队时延均迅速增大,各节点均存在大量待发分组排队的情况,并且随着仿真时间的增加,待发分组迅速增加。端到端时延主要由传输时延、传播时延、处理时延和排队时延组成,此时,排队时延的占比较大。未使用RTDB算法时,大部分实时性报文的排队时延等于默认的最大排队时延3 s;使用RTDB算法后,大部分实时性报文的排队时延等于时延阈值300 ms。仿真结果表明,在当前仿真场景下,Link16和Link11在未使用RTDB算法时报文的端到端平均时延均接近3 000 ms;而使用RTDB算法后,Link16的端到端平均时延不到1 000 ms,Link11的端到端平均时延约为1 000 ms。首先,分析Link11的网络负载为2 500 bit/s的情况。根据理论分析结果,代入
\lambda \geqslant \mu 时的增益公式(式(15)),得到Link11的最大增益为78.1%。仿真结果表明,2 500 bit/s下的增益为66.6%,符合理论分析情况。同理,依次验证Link11在其他负载下,以及Link16在各网络负载下的增益,结果显示均符合理论分析结果。由图11和图12可知,在满负载情况下,2种情况下的网络吞吐率一致,说明RTDB算法丢弃部分时效性很差的实时性报文不会影响到整个网络的吞吐率。
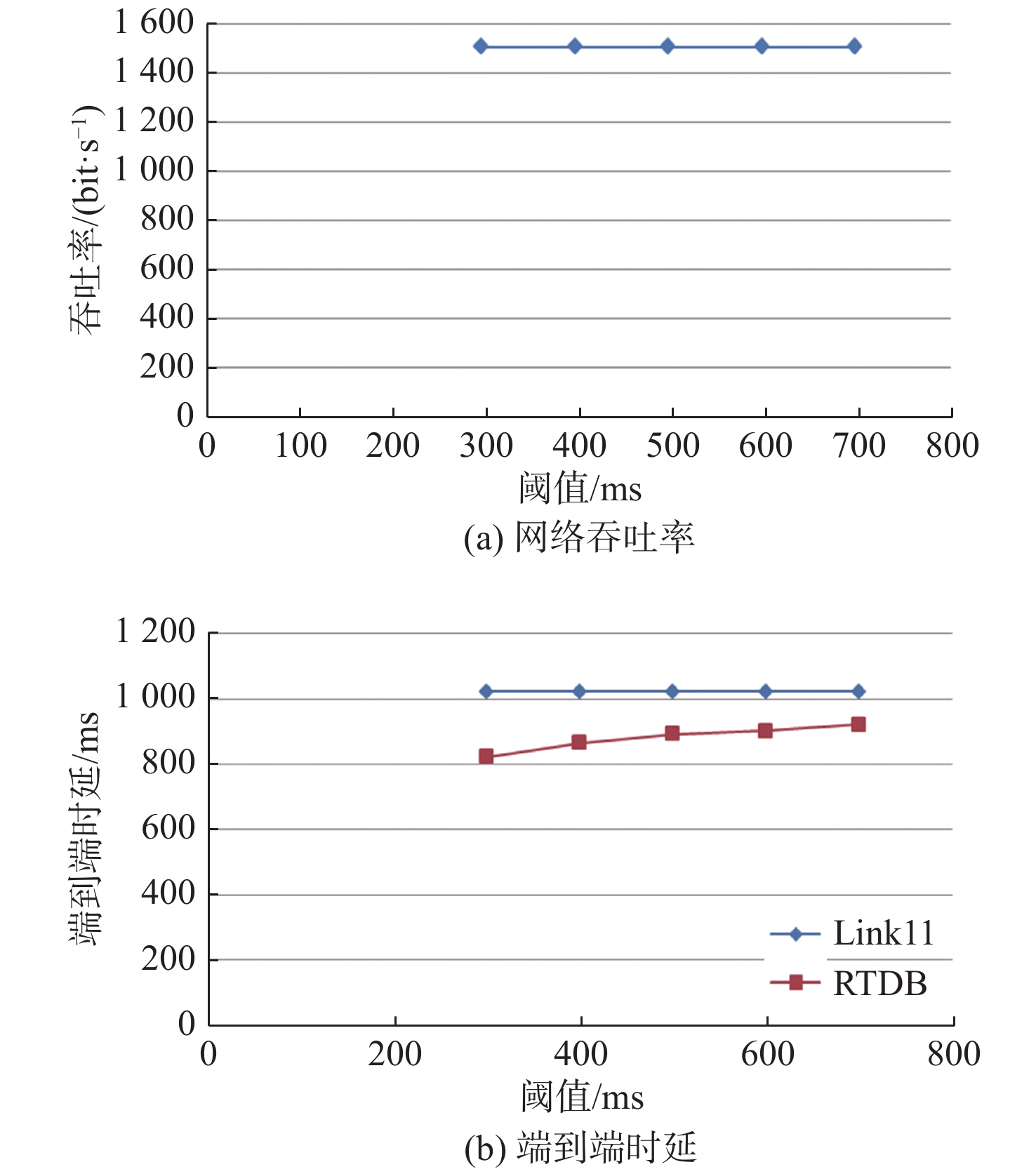
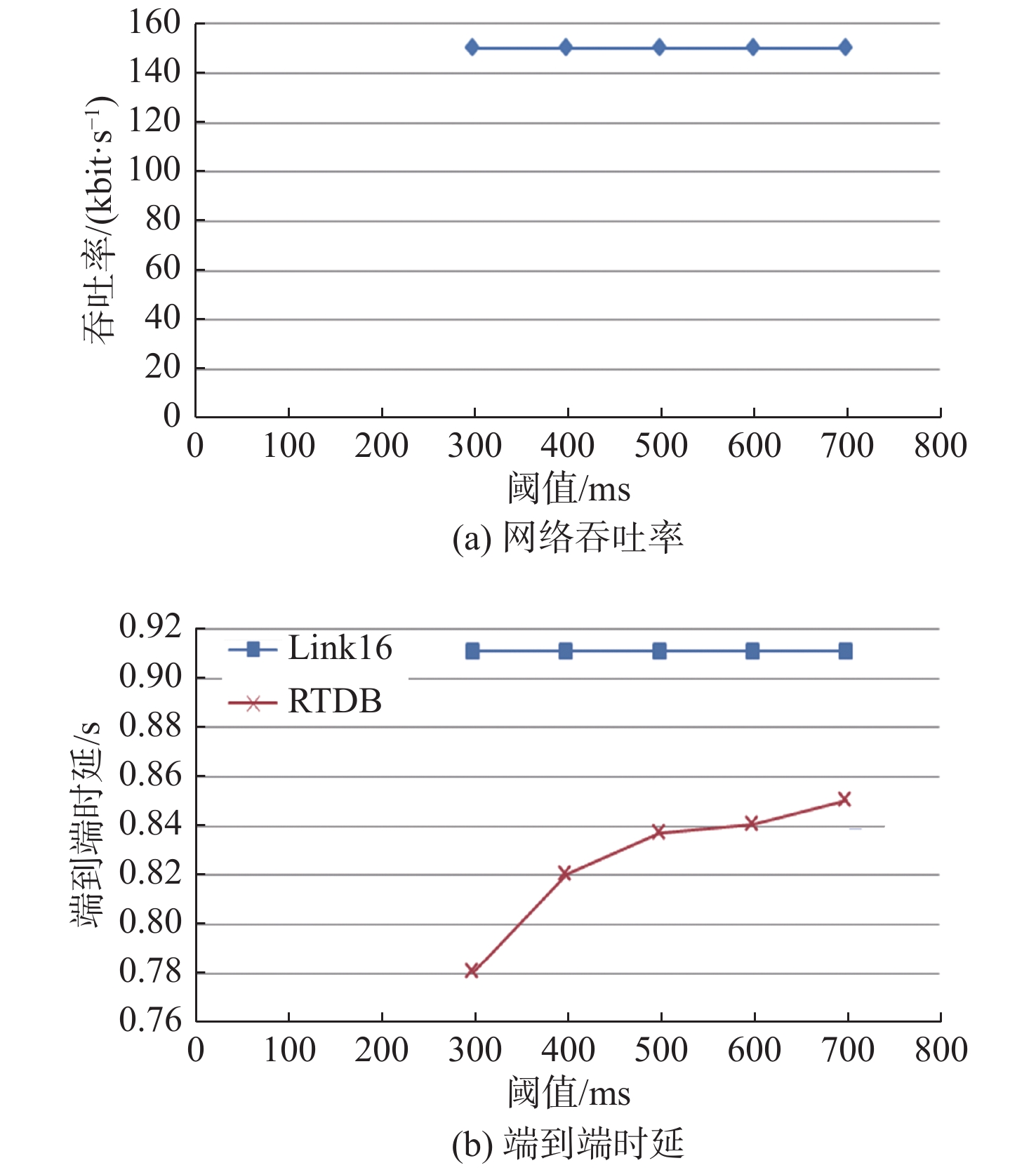
下面,分析RTDB算法中设置不同的阈值对网络性能的影响程度。仿真场景不变,在Link11情况下,假定当前负载为中等负载1 500 bit/s,分别将阈值设置为300,400,500,600和700 ms进行仿真,得到网络吞吐率、端到端平均传输时延如图13所示。
![]() 图 13 固定负载情况下数据链Link11的网络吞吐率和端到端时延随阈值的变化Figure 13. Variation of network throughput and end-to-end delay with threshold of Link11 at fixed load condition
图 13 固定负载情况下数据链Link11的网络吞吐率和端到端时延随阈值的变化Figure 13. Variation of network throughput and end-to-end delay with threshold of Link11 at fixed load condition在Link16情况下,设置当前负载为中等负载150 kbit/s,分别将阈值设置为300,400,500,600和700 ms进行仿真,得到网络吞吐率、端到端平均传输时延如图14所示。
分析阈值的变化采用中等网络负载。由图13、图14及中等负载情况下的分析结果可知,在当前情况下,随着阈值逐渐增大,数据链Link11和Link16的端到端平均时延均呈逐渐接近于未使用算法时的趋势,算法增益逐渐降低。随着阈值的增大,阈值对实时性报文的约束能力越来越低,可以预见,当阈值超过稳态平均时延时,算法将趋于失效。
![]() 图 14 固定负载情况下数据链Link16的网络吞吐率和端到端时延随阈值的变化Figure 14. Variation of network throughput and end-to-end delay with threshold of Link16 at fixed load condition
图 14 固定负载情况下数据链Link16的网络吞吐率和端到端时延随阈值的变化Figure 14. Variation of network throughput and end-to-end delay with threshold of Link16 at fixed load condition由理论分析情况可知,理论极限情况下阈值可设置为0,仿真情况也显示,设置的阈值越小,算法带来的时延增益越大,当设置的阈值远大于理论值时,算法的约束力将逐渐降低,导致算法增益逐渐变小。但仿真情况并未按理论值来设置阈值,这是因为在实际情况中肯定会存在一定的排队时延,若是按理论值进行设置有可能会造成大量丢包,甚至导致所有实时性报文因未达到阈值要求而被全部丢弃。在实际作战场景中,需根据不同实时性类型报文的战技指标设置不同的阈值。
综上所述,在大量数据业务传输场景以及存在一定排队情况的中等负载传输场景中,所提出的RTDB算法在不影响吞吐率的同时,能有效降低实时性报文的端到端时延,这在一定程度上增加了实时性报文的时效性。
5. 结 语
本文提出了基于实时性区分的舰载网络传输优化算法−RTDB算法,该算法是根据实时性报文的时效特性来优化报文的排队时延。通过对报文实时性标志位字段的解析,得到该报文的时延阈值,并根据实际时延与阈值的比对情况对报文进行不同的处理,来尽量降低实时性报文的端到端传输时延,提高实时性报文的时效性。
之后,基于美国海军广泛使用的战术数据链Link11和Link16,对RTDB算法的增益性进行理论推算,得出了RTDB算法的增益范围,并通过NS3平台对未使用RTDB算法和使用了RTDB算法的情况进行了仿真。仿真结果显示,在高负载情况下,RTDB算法能在不降低网络吞吐率的情况下极大地优化实时性报文的端到端时延。
对于存在大量旧型舰船的国家,若是存在编队作战需求,大量的数据收发可能会导致旧型舰船系统过载。而本文提出的RTDB算法易于实现,在一定程度上可以解决类似的急需,同时能提高情报类消息的时效性。后续,将结合实时性区分研究动态时隙分配的可行性,致力于在提高实时性报文时效性的基础上,进一步提升网络吞吐率。
-
![]()
图 7 低负载情况下数据链Link11的网络吞吐率和端到端时延随网络负载的变化
Figure 7. Variation of network throughput and end-to-end delay with network load of Link11 at low load condition
![]()
图 8 低负载情况下数据链Link16的网络吞吐率和端到端时延随网络负载的变化
Figure 8. Variation of network throughput and end-to-end delay with network load of Link16 at low load condition
![]()
图 9 中等负载下数据链Link11的网络吞吐率和端到端时延随网络负载的变化
Figure 9. Variation of network throughput and end-to-end delay with network load of Link11 at middle load condition
![]()
图 10 中等负载下数据链Link16的网络吞吐率和端到端时延随网络负载的变化
Figure 10. Variation of network throughput and end-to-end delay with network load of Link16 at middle load condition
![]()
图 11 满负载下数据链Link11的网络吞吐率和端到端时延随网络负载的变化
Figure 11. Variation of network throughput and end-to-end delay with network load of Link11 at full load condition
![]()
图 12 满负载下数据链Link16的网络吞吐率和端到端时延随网络负载的变化
Figure 12. Variation of network throughput and end-to-end delay with network load of Link16 at full load condition
![]()
图 13 固定负载情况下数据链Link11的网络吞吐率和端到端时延随阈值的变化
Figure 13. Variation of network throughput and end-to-end delay with threshold of Link11 at fixed load condition
-
[1] 周朋. 美军战术数据链发展分析及启示[J]. 科技视界, 2017(5): 328–329. ZHOU P. Analysis and inspiration of development of US. forces' tactical data links[J]. Science & Technology Vision, 2017(5): 328–329 (in Chinese).
[2] 刘梦馨. 多用户通信数据链的半实体终端仿真[D]. 北京: 北京邮电大学, 2019. LIU M X. Simulation research of mixed termination about multi-user communication data link[D]. Beijing: Beijing University of Posts and Telecommunications, 2019 (in Chinese).
[3] 王国栋. 短波战术数据链Link-11技术体制研究[D]. 西安: 西安电子科技大学, 2010. WANG G D. Research on Link-11 technique system for HF tactics data link[D]. Xi'an: Xidian University, 2010 (in Chinese).
[4] LIN C, CAI X S, SU Y X, et al. A dynamic slot assignment algorithm of TDMA for the distribution class protocol using node neighborhood information[C]//Proceedings of the 2017 11th IEEE International Conference on Anti-Counterfeiting, Security, and Identification (ASID). Xiamen: IEEE, 2017: 138–141.
[5] HADDED M, MUHLETHALER P, LAOUITI A, et al. A centralized TDMA based scheduling algorithm for real-time communications in vehicular ad hoc networks[C]//Proceedings of the 2016 24th International Conference on Software, Telecommunications and Computer Networks (SoftCOM). Split, Croatia: IEEE, 2016: 1–6.
[6] CHLAMTAC I, FARAGÓ A, ZHANG H B. Time-spread multiple-access (TSMA) protocols for multihop mobile radio networks[J]. IEEE/ACM Transactions on Networking, 1997, 5(6): 804–812. doi: 10.1109/90.650140
[7] ORAKWUE C, AL-MOUSA Y, MARTIN N, et al. A cluster based time division multiple access scheme for surveillance networks using directional antennas[C]//Proceedings of the 2010 4th International Conference on Signal Processing and Communication Systems. Gold Coast, QLD, Australia: IEEE, 2010.
[8] 杨志飞, 刘春茂, 王晓攀, 等. Link16数据链网络同步的改进算法[J]. 舰船电子工程, 2011, 30(12): 99–101. YANG Z F, LIU C M, WANG X P, et al. An improving network synchronization algorithm for Link16[J]. Ship Electronic Engineering, 2011, 30(12): 99–101 (in Chinese).
[9] 董文龙, 李有根. 浅析美军数据链主要消息格式[J]. 无线互联科技, 2013(2): 32. DONG W L, LI Y G. Analysis of the main message formats of the US army data link[J]. Wireless Interconnect Technology, 2013(2): 32 (in Chinese).
[10] 李建东, 盛敏. 通信网络基础[M]. 北京: 高等教育出版社, 2004. LI J D, SHENG M. Communication network foundation[M]. Beijing: Higher Education Press, 2004 (in Chinese).
[11] 杨春周, 滕克难, 战希臣, 等. 舰艇编队CEC系统作战效能模型研究[J]. 计算机仿真, 2009, 26(9): 12–14, 23. doi: 10.3969/j.issn.1006-9348.2009.09.006 YANG C Z, TENG K N, ZHAN X C, et al. A combat effectiveness model of cooperative engagement capability for surface ship formation[J]. Computer Simulation, 2009, 26(9): 12–14, 23 (in Chinese). doi: 10.3969/j.issn.1006-9348.2009.09.006
[12] 倪京兆. 基于稳定匹配的LTE无线资源管理及NS3仿真分析[D]. 西安: 西安电子科技大学, 2013. NI J Z. The study of stable matching based LTE wireless resource management and NS3 simulation analysis[D]. Xi'an: Xidian University, 2013 (in Chinese).
[13] 常前锋. 无线局域网性能增强技术研究[D]. 西安: 西安电子科技大学, 2016. CHANG Q F. The research on performance enhancement technologies in WLAN[D]. Xi'an: Xidian University, 2016 (in Chinese).
[14] 崔强, 李敬辉, 吴晶. 航母编队防空队形配置方法研究进展[J]. 舰船电子工程, 2017, 37(8): 1–4, 10. doi: 10.3969/j.issn.1672-9730.2017.08.001 CUI Q, LI J H, WU J. Research progress on air defense formation for carrier battle group[J]. Ship Electronic Engineering, 2017, 37(8): 1–4, 10 (in Chinese). doi: 10.3969/j.issn.1672-9730.2017.08.001
 下载:
下载:
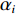
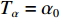
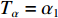
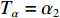
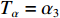
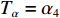
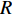

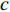
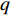
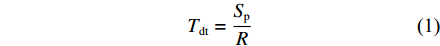

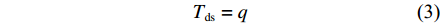
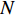
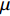
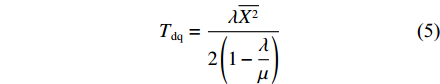
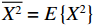
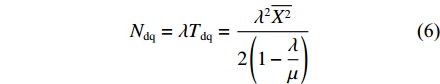
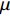
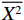
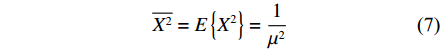

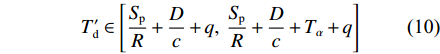
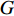
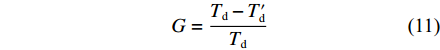
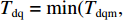
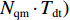
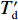
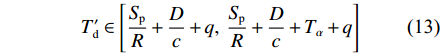

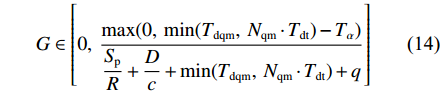
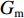
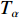

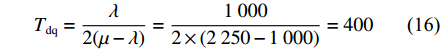
计量
- 文章访问数: 502
- HTML全文浏览量: 282
- PDF下载量: 25
